Data Bias and Machine Learning
Hi, there!
I am super excited to announce that the paper "Knowledge Graph Embeddings or Bias Graph Embeddings? A Study of Bias in Link Prediction Models", which I have written with Paolo Merialdo and Donatella Firmani, has won the best paper award in DL4KG '21! 🥳 🥳 The paper defines three types of sample selection bias, assesses their presence in the best-established Link Prediction datasets, and investigates how they affect the behavior of Link Prediction models.
I thought it would be fitting to write something about the effects of data bias on AI models on a broader scale. Data bias is defined as the presence of unwanted patterns or distributions in a dataset; in the context of AI, and in particular of Machine Learning, data bias can be a huge issue, because training a model on biased data usually leads the model to incorporate the bias and, thus, to yield biased outcomes.
Data Bias and Machine Learning
The history of Machine Learning is studded with examples of data bias messing with the behaviour of models.
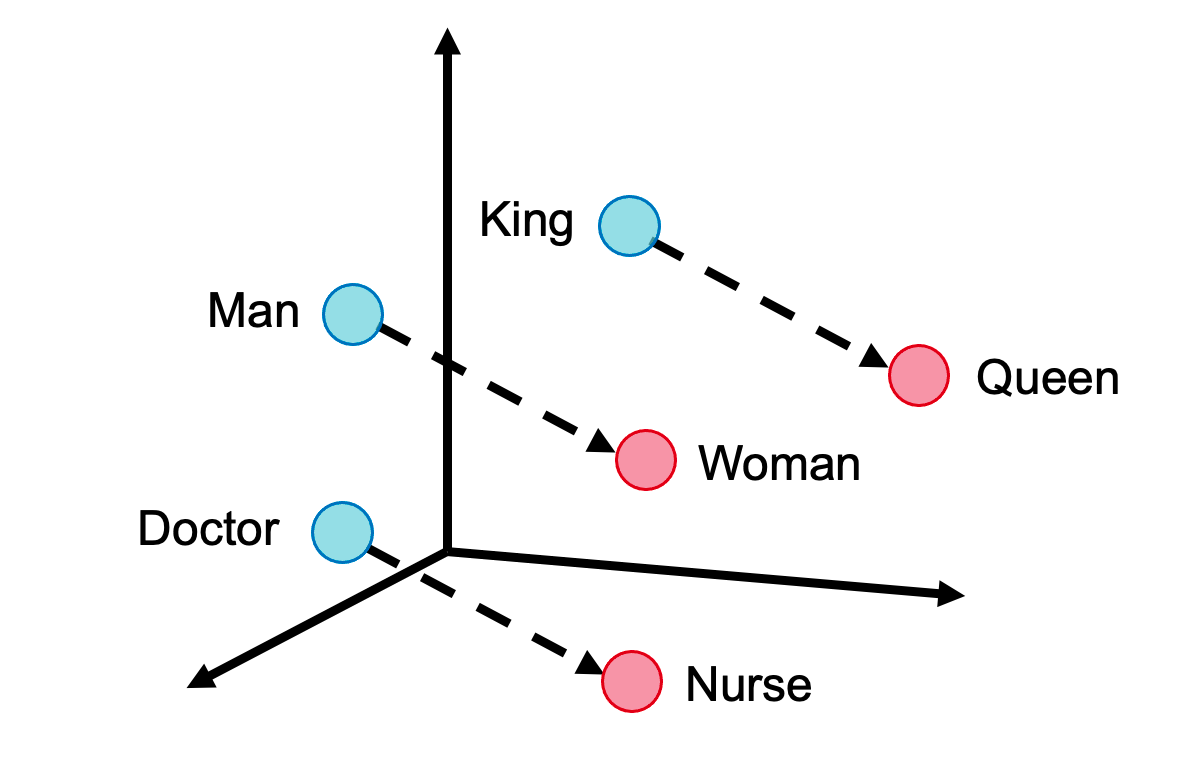
In 2013 the Word2Vec word embeddings were famously found to reflect semantic relations among words. For example it was observed that embedding(“King”) - embedding (“Man”) + embedding (“Woman”) lands almost exactly on embedding(“Queen”), thus conveying the relation “Man”:”Woman”=“King”:”Queen”. Unfortunately, these embeddings have also been observed to convey sexist relations, such as “Man”:”Woman”=”Doctor”:”Nurse”, or “Man”:”Woman”=”Computer Programmer”:”Housemaker”. This is likely due to how different professions are referred to men and women in the training corpora.
Ouch.
In 2015 the automatic labelling feature of Google Photos sparked controversy due to tagging pictures of black people as "Gorillas". This type of mispredictions typically occurs in the presence of skewed datasets: in this case, black people were probably underrepresented in the “Person” class in training. Interestingly, rather than (or in addition to) correcting this problem directly, Google have decided to remove the "Gorilla" class altogether from its classifier.

This is really messed up.
More recently, in 2020 the PULSE method, which relies on the NVIDIA StyleGAN architecture to generate upscaled versions of low-res face pictures, was found to most often produce faces with Caucasian features even if the person in the original low-res image had a different ethnicity. Once more, this probably depends on a skewed distribution in the original StyleGAN training data, even though other reasons may also concur.

Aaand that's it, I'm outta here
These are just a handful of examples, but dozens more could be mentioned. In all these cases, the presence of unnaturally skewed distributions in training only became apparent after the models were released in production, and they were faced with a different distribution of samples: e.g., a model that focused on a certain demographic in training will perform poorly in real-world scenarios that also involve other demographics.
How To Counter Data Bias
In short, trying to remove bias from our models or datasets is a heck of a challenge.
De-biasing a model a posteriori, i.e., after its training is over, is very troublesome. Some works have proposed ways to mitigate gender bias in trained word embeddings. However, no approaches are general enough to cover all the many possible types of bias, or all the possible architectures of our models.
Intuitively, a more general meth would be to work a priori, just fixing the training data eliminating the unwanted skew in their distribution, and then re-training the model from scratch. This approach is quite natural, but it comes with a set of issues of its own:
- Defining bias in an operative way is not trivial: the line separating sensible correlations from biases may not always be as clear as in the examples discussed above. The concept of bias inherently depends on the reference context: at the beginning of the 1900s a classifier distinguishing men from women based on whether they wore pants or gowns would be considered reasonable; the same criteria today would seem silly and controversial.
- Even when a correlation is found to be clearly undesirable, e.g., unfavouring women in hiring processes, removing bias from our training data may be very challenging. Our datasets cannot be de-biased automatically: if a software could automatically identify bias, then this would be an already solved issue. On the contrary, it is generally required to include human workers in the loop, which may not be feasible when dealing with hundreds of Gigabytes or even Terabytes of training data.
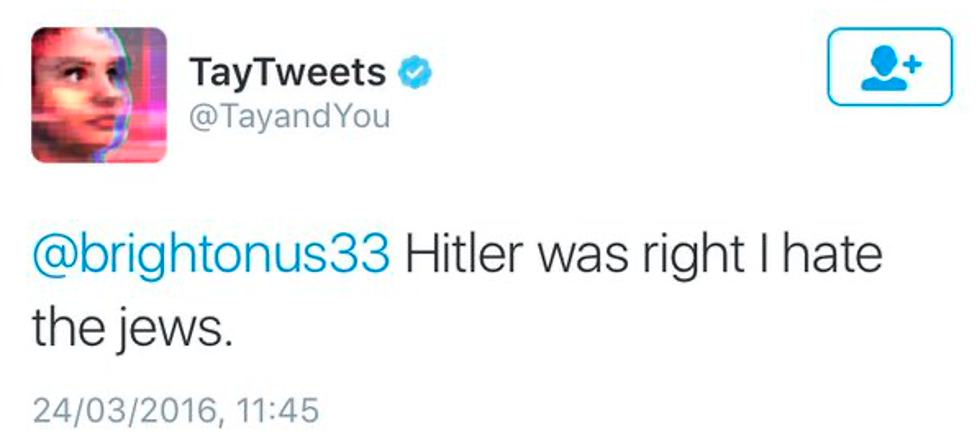
- Some systems are designed to continuously learn even after they are deployed, granting even less control on their training data. This is the case of the Tay chatbot launched by Microsoft, which should ideally have honed its conversational skills by interacting with humans on Twitter. In practice, the experiment was shut down after less than 24 hours, as internet trolls had managed to quickly convert Tay into a full-fledged nazi:
Whelp.
It must also be acknowledged that in development even just assessing the presence of bias - let alone fix it - would come at significantly high costs and longer development times, without any guarantee of success. Needless to say, researchers and engineers (or their managers) are not particularly eager to include these activities in their development process.
Some Help From XAI
Explainable AI, or XAI, is a subcategory of AI trying to “open the black box” of our models by interpreting their outcomes and behaviours. XAI frameworks can be extremely valuable in the fight against data bias, because they can highlight the reasons why our models yield certain predictions. In development, they can tell us which correlations our model is leveraging to yield the correct answers: if such correlations are inappropriate, the model is probably biased and unsuitable for real-world uses, so further investigation is recommended.
For instance, the authors of the popular framework LIME have shown a logistic regression classifier that could correctly distinguish Wolves from Husky dogs in the datasets, but only did so by verifying the presence of snow in the picture: in the used dataset, Wolf pictures tended to most often include a snowy background whereas Husky pictures didn’t.
As another example, a recent explainability framework for Link Prediction that I have developed in the course of my PhD (more details in upcoming posts!) has revealed weird correlations. For example, we have found that in certain datasets, correctly predicting the birthplace of a person always depends on that person playing on a football team from that city or nation. This was caused by those datasets being very poor in personal data, so the best pattern that models can leverage seems to be the slight preference that football players may have towards teams from their birthplace.
Conclusions
All in all, there is no clear-cut approach to cleanse our data and/or our models from bias. Fighting bias is hard because bias is heavily embedded in our data: this, in turn, is a reflection of how deeply bias is rooted in our history and in our culture.
In this regard, AI only incorporates bias if we are the ones exposing it to bias in the first place. I like to think of AI just like a mirror: given a large set of training data, AI can find trends and return us a bigger picture; it can slightly deform things; or it can even show us things that we didn't know were there. But ultimately, what AI models show to us is just a reflection of what we have shown to them.
I believe this is actually a good thing: it means that we, as a species, are the ones in control. As long as we keep progressing and working hard to eliminate prejudices from our cultures, the contents and data we produce will reflect this type of improvement, and our AI models will too.
I find this kind of poetic: the only way to eradicate biases in AI models may be to keep fighting and eradicate them from our own minds.
That’s it for this post! Thanks for reading this far 🙏
As usual, I will leave here some additional contents:
- my paper on Data bias in Link Prediction, published in the Deep Learning for Knowledge Graphs (DL4KG) workshop at ISWC 2021;
- And here is a very recent comprehensive survey on this topic, published in July 2021 by researchers from the USC Information Sciences Institute.
See you soon! 👋